Tokenization¶
Prerequisites:
Access to a Project on the Konfuzio Server.
Data Layer concepts of Konfuzio: Document, Project, Bbox, Span, Label
Difficulty: Easy
Goal: Be familiar with the concept of tokenization and master how different tokenization approaches can be used with Konfuzio.
Environment¶
You need to install the Konfuzio SDK before diving into the tutorial.
To get up and running quickly, you can use our Colab Quick Start notebook.
![]()
As an alternative you can follow the installation section to install and initialize the Konfuzio SDK locally or on an environment of your choice.
Introduction¶
In this tutorial, we will explore the concept of tokenization and the various tokenization strategies available in the Konfuzio SDK. Tokenization is a foundational tool in natural language processing (NLP) that involves breaking text into smaller units called tokens. We will focus on the WhitespaceTokenizer, Label-Specific RegexTokenizer, ParagraphTokenizer, and SentenceTokenizer as different tools for different tokenization tasks. Additionally, we will discuss how to choose the right tokenizer and how to verify that a tokenizer has found all Labels.
Whitespace Tokenization¶
The WhitespaceTokenizer, part of the Konfuzio SDK, is a simple yet effective tool for basic tokenization tasks. It segments text into tokens using whitespaces, tabs, and newlines as natural delimiters.
Use case: retrieving the word-level Bounding Boxes for a Document¶
In this section, we will walk through how to use the WhitespaceTokenizer to extract word-level Bounding Boxes for a Document.
We will use the Konfuzio SDK to tokenize the Document and identify word-level Spans, which can then be visualized or used to extract Bounding Box information.
First, we import necessary modules:
from copy import deepcopy
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.regex import WhitespaceTokenizer
Next, initialize a Project and a Document instance. The variables TEST_PROJECT_ID and TEST_DOCUMENT_ID are placeholders that need to be replaced with actual values when running these steps. Make sure to use a Project and a Document to which you have access.
project = Project(id_=TEST_PROJECT_ID, update=True)
document = project.get_document_by_id(TEST_DOCUMENT_ID)
We create a copy of the Document object to make sure it contains no Annotations. This is needed because during tokenization, new 1-Span-long Annotations are created.
document = deepcopy(document)
Then, we tokenize the Document using the Whitespace Tokenizer. It creates new Spans in the Document.
tokenizer = WhitespaceTokenizer()
tokenized = tokenizer.tokenize(document)
Now we can visually check that the Bounding Boxes are correctly assigned.
tokenized.get_page_by_index(0).get_annotations_image(display_all=True)

Observe how each individual word is enclosed in a Bounding Box. Also note that there are no Labels in the Annotations associated with the Bounding Boxes, thereby the placeholder ‘NO_LABEL’ is shown above each Bounding Box.
Each Bounding Box is associated with a specific word and is defined by four coordinates:
x0 and y0 specify the coordinates of the bottom left corner;
x1 and y1 specify the coordinates of the top right corner
This is used to determine the size and position of the Box on the Page.
All Bounding Boxes calculated after tokenization can be obtained as follows:
span_bboxes = [span.bbox() for span in tokenized.spans()]
Let us inspect the first 10 Bounding Boxes’ coordinates to verify that each comprises 4 coordinate points.
span_bboxes[:10]
[Bbox: x0: 426.0 x1: 442.8 y0: 808.831 y1: 817.831 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 462.48 x1: 568.801 y0: 808.831 y1: 817.831 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 48.48 x1: 106.32 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 110.64 x1: 125.762 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 129.6 x1: 226.321 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 246.72 x1: 263.52 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 270.0 x1: 317.521 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 324.48 x1: 347.04 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 468.48 x1: 527.04 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823),
Bbox: x0: 535.92 x1: 548.642 y0: 797.311 y1: 806.311 on Page Page 0 in Virtual Document None (44823)]
To summarize, here is the full code:
from copy import deepcopy
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.regex import WhitespaceTokenizer
project = Project(id_=TEST_PROJECT_ID)
document = project.get_document_by_id(TEST_DOCUMENT_ID)
document = deepcopy(document)
tokenizer = WhitespaceTokenizer()
tokenized = tokenizer.tokenize(document)
tokenized.get_page_by_index(0).get_annotations_image(display_all=True)
span_bboxes = [span.bbox() for span in tokenized.spans()]
span_bboxes[:10]
Note: The variables TEST_PROJECT_ID and TEST_DOCUMENT_ID are placeholders and need to be replaced. Remember to use a Project and Document id to which you have access.
Regex Tokenization for Specific Labels¶
In some cases, especially when dealing with intricate Annotation strings, a custom RegexTokenizer can offer a powerful solution. Unlike the basic WhitespaceTokenizer, which split text based on spaces, tabs and newlines, RegexTokenizer utilizes regular expressions to define complex patterns for identifying and extracting tokens. This tutorial will guide you through the process of creating and training your own RegexTokenizer, providing you with a versatile tool to handle even the most challenging tokenization tasks. Let’s get started!
In this example, we will see how to find regular expressions that match with occurrences of the “Lohnart” (which approximately means type of salary in German) Label in the training data, namely Documents that have been annotated by hand.
First, we import necessary modules:
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.regex import RegexTokenizer
from konfuzio_sdk.tokenizer.base import ListTokenizer
Then, we initialize the Project and obtain the Category. We need to obtain an instance of the Category which will be used later to achieve what we need: find the best regular expression matching our Label of interest.
my_project = Project(id_=TEST_PROJECT_ID)
category = my_project.get_category_by_id(id_=TEST_PAYSLIPS_CATEGORY_ID)
We use the ListTokenizer, a class that provides a way to organize and apply multiple tokenizers to a Document, allowing for complex tokenization pipelines in natural language processing tasks. In this case, we simply use to hold our regular expression tokenizers.
tokenizer_list = ListTokenizer(tokenizers=[])
Retrieve the “Lohnart” Label using its name.
label = my_project.get_label_by_name("Lohnart")
Find regular expressions and create RegexTokenizers. We now use Label.find_regex to algorithmically search for the best fitting regular expressions matching the Annotations associated with this Label. Each RegexTokenizer is collected in the container object tokenizer_list.
regexes = label.find_regex(category=category)
Let’s see how many and which regexes have been found.
print(len(regexes))
for regex in regexes:
print(regex)
regex_tokenizer = RegexTokenizer(regex=regex)
tokenizer_list.tokenizers.append(regex_tokenizer)
2
(?:(?P<Label_861_N_4420346_1758>\d\d\d\d))[ ]{1,2}
[ ]{2,}(?:(?P<Label_861_N_4420346_1758>\d\d\d\d))[ ]{1,2}
Finally, we can use the TokenizerList instance to create new NO_LABEL Annotations for each string in the Document matching the regex patterns found.
document = my_project.get_document_by_id(TEST_DOCUMENT_ID)
document = tokenizer_list.tokenize(document)
To summarize, here is the complete code of our regex tokenization example.
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.regex import RegexTokenizer
from konfuzio_sdk.tokenizer.base import ListTokenizer
my_project = Project(id_=TEST_PROJECT_ID)
category = my_project.get_category_by_id(id_=TEST_PAYSLIPS_CATEGORY_ID)
tokenizer_list = ListTokenizer(tokenizers=[])
label = my_project.get_label_by_name("Lohnart")
regexes = label.find_regex(category=category)
print(len(regexes))
for regex in regexes:
print(regex)
regex_tokenizer = RegexTokenizer(regex=regex)
tokenizer_list.tokenizers.append(regex_tokenizer)
document = my_project.get_document_by_id(TEST_DOCUMENT_ID)
document = tokenizer_list.tokenize(document)
Paragraph Tokenization¶
The ParagraphTokenizer class is a specialized tool designed to segment a Document into paragraphs. It offers two modes of operation: detectron and line_distance.
To determine the mode of operation, the mode constructor parameter is used, it can take two values: detectron (default) or line_distance. In detectron mode, the Tokenizer uses a fine-tuned Detectron2 model to assist in Document segmentation. While this mode tends to be more accurate, it is slower as it requires making an API call to the model hosted on Konfuzio servers. On the other hand, the line_distance mode uses a rule-based approach that is faster but less accurate, especially with Documents having two columns or other complex layouts.
line_distance Approach¶
It provides an efficient way to segment Documents based on line heights, making it particularly useful for simple, single-column formats. Although it may have limitations with complex layouts, its swift processing and relatively accurate results make it a practical choice for tasks where speed is a priority and the Document structure isn’t overly complicated.
Parameters¶
The behavior of the line_distance approach can be adjusted with the following parameters.
line_height_ratio: (Float) Specifies the ratio of the median line height used as a threshold to create a new paragraph when using the Tokenizer inline_distancemode. The default value is 0.8, which is used as a coefficient when calculating median vertical character size for Page. If you find that the Tokenizer is not creating new paragraphs when it should, you can try lowering this value. Alternatively, if the Tokenizer is creating too many paragraphs, you can try increasing this value.height: (Float) This optional parameter allows you to define a specific line height threshold for creating new paragraphs. If set to None, the Tokenizer uses an intelligently calculated height threshold.
Using the ParagraphTokenizer in line_distance mode boils down to creating a ParagraphTokenizer instance and use it do tokenize a Document.
Let’s import the needed modules and initialize the Project and the Document.
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.paragraph_and_sentence import ParagraphTokenizer
project = Project(id_=TEST_PROJECT_ID)
document = project.get_document_by_id(TEST_DOCUMENT_ID)
Initialize the ParagraphTokenizer and tokenize the Document.
tokenizer = ParagraphTokenizer(mode='line_distance')
document = tokenizer(document)
Then, we fetch the image representing the first page of the Document to visualize the Annotations generated by the tokenizer. Set display_all=True to show NO_LABEL Annotations.
document.get_page_by_index(0).get_annotations_image(display_all=True)

Due to the complexity of the Document we processed, the line_distance approach does not perform very well. We can see that a simpler Document that has a more linear structure gives better results:
from konfuzio_sdk.data import Project, Document
from konfuzio_sdk.tokenizer.paragraph_and_sentence import ParagraphTokenizer
from copy import deepcopy
my_project = Project(id_=TEST_PROJECT_ID)
sample_doc = Document.from_file("sample.pdf", project=my_project, sync=True)
deepcopied_doc = deepcopy(sample_doc)
tokenizer = ParagraphTokenizer(mode='line_distance')
tokenized_doc = tokenizer(deepcopied_doc)
tokenized_doc.get_page_by_index(0).get_annotations_image(display_all=True)

Note that this example uses a PDF file named ‘sample.pdf’, you can download this file here in case you wish to try running this code.
Detectron (CV) Approach¶
With the Computer Vision (CV) approach, we can create Labels, identify figures, tables, lists, texts, and titles, thereby giving us a comprehensive understanding of the Document’s structure.
Using the Computer Vision approach might require more processing power and might be slower compared to the line_distance approach, but the significant leap in the comprehensiveness of the output makes it a powerful tool.
Parameters¶
create_detectron_labels: (Boolean, default: False) if set to True, Labels will be created and assigned to the Document. Labels may includefigure,table,list,textandtitle. If this option is set to False, the Tokenizer will createNO_LABELAnnotations.
Using a Tokenizer in detectron mode boils down to passing detectron ot the mode argument of the ParagraphTokenizer.
Make necessary imports, initialize the Project and the Document.
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.paragraph_and_sentence import ParagraphTokenizer
project = Project(id_=TEST_PROJECT_ID)
document = project.get_document_by_id(TEST_DOCUMENT_ID)
Initialize the tokenizer and tokenize the Document.
tokenizer = ParagraphTokenizer(mode='detectron', create_detectron_labels=True)
tokenized = tokenizer(document)
tokenized.get_page_by_index(0).get_annotations_image()
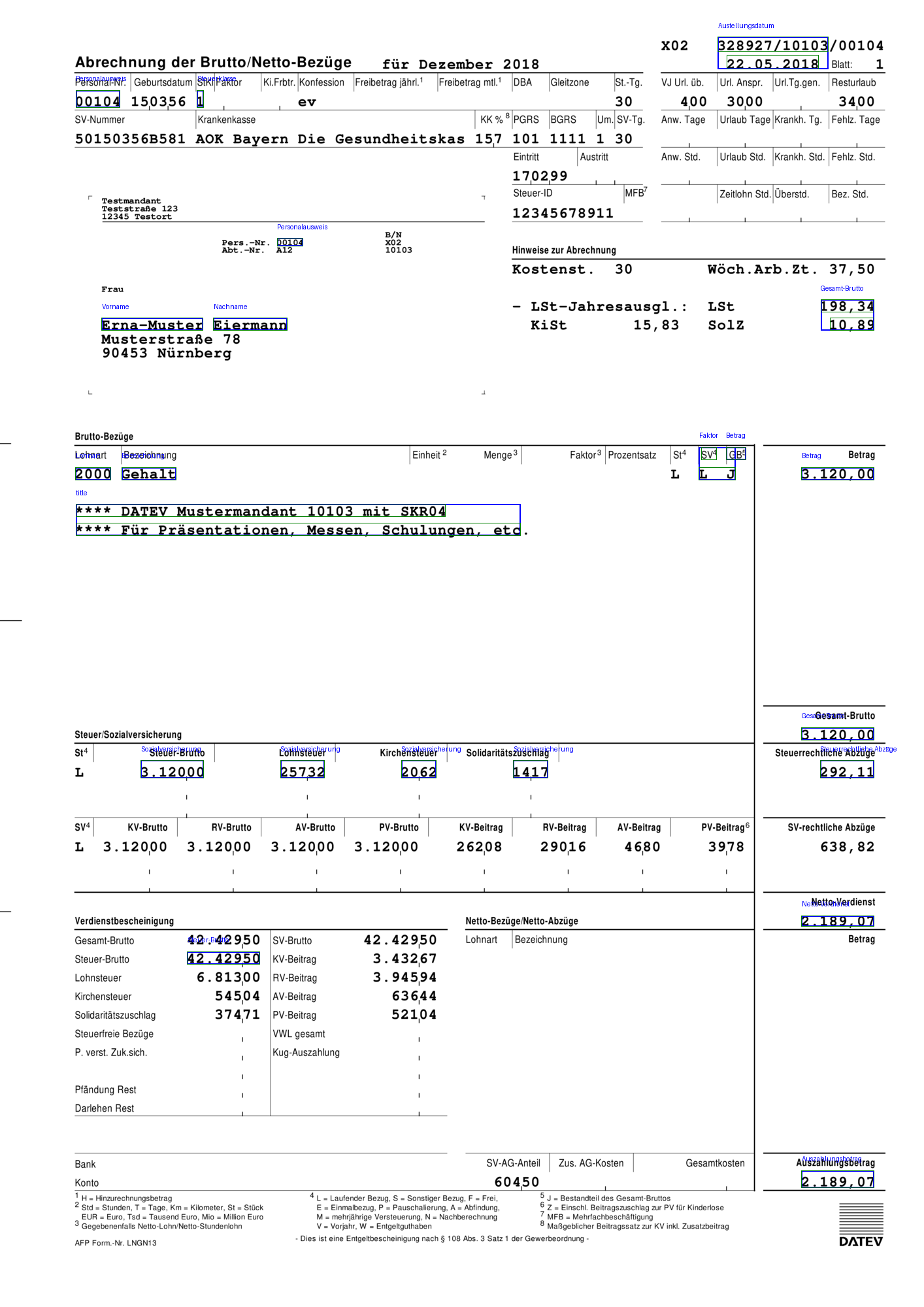
Comparing this result to tokenizing the same Document with the line_distance approach it is evident that the detectron mode can extract a meaningful structure from a relatively complex Document.
Sentence Tokenization¶
The SentenceTokenizer is a specialized tokenizer designed to split text into sentences. Similarly to the ParagraphTokenizer, it has two modes of operation: detectron and line_distance, and accepts the same additional parameters: line_height_ratio, height and create_detectron_labels.
To use it, import the necessary modules, initialize the Project, the Document, and the Tokenizer and tokenize the Document.
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.paragraph_and_sentence import SentenceTokenizer
from copy import deepcopy
project = Project(id_=TEST_PROJECT_ID, update=True)
doc = project.get_document_by_id(YOUR_DOCUMENT_ID)
tokenizer = SentenceTokenizer(mode='detectron')
tokenized = tokenizer(doc)
Visualize the output:
tokenized.get_page_by_index(1).get_annotations_image(display_all=True)

Choosing the right tokenizer¶
When it comes to natural language processing (NLP), choosing the correct tokenizer can make a significant impact on your system’s performance and accuracy. The Konfuzio SDK offers several tokenization options, each suited to different tasks:
WhitespaceTokenizer: Perfect for basic word-level processing. This tokenizer breaks text into chunks separated by whitespaces, tabs and newlines. It is ideal for straightforward tasks such as basic keyword extraction.
Label-Specific RegexTokenizer: Known as character detection mode on the Konfuzio server, this tokenizer offers more specialized functionality. It uses Annotations of a Label within a training set to pinpoint and tokenize precise chunks of text. It is especially effective for tasks like entity recognition, where accuracy is paramount. By recognizing specific word or character patterns, it allows for more precise and nuanced data processing.
ParagraphTokenizer: Identifies and separates larger text chunks - paragraphs. This is beneficial when your text’s interpretation relies heavily on the context at the paragraph level.
SentenceTokenizer: Segments text into sentences. This is useful when the meaning of your text depends on the context provided at the sentence level.
Choosing the right Tokenizer is a matter of understanding your NLP task, the structure of your data, and the degree of detail your processing requires. By aligning these elements with the functionalities provided by the different tokenizers in the Konfuzio SDK, you can select the best tool for your task.
Verify that a tokenizer finds all Labels¶
To help you choose the right tokenizer for your task, it can be useful to try out different tokenizers and see which Spans are found by which tokenizer. The Label class provides a method called spans_not_found_by_tokenizer that can he helpful in this regard.
Here is an example of how to use the Label.spans_not_found_by_tokenizer method. This will allow you to determine if a RegexTokenizer is suitable at finding the Spans of a Label, or what Spans might have been annotated wrong. Say, you have a number of Annotations assigned to the Austellungsdatum Label and want to know which Spans would not be found when using the WhitespaceTokenizer. You can follow this example to find all the relevant Spans.
from konfuzio_sdk.data import Project
from konfuzio_sdk.tokenizer.regex import WhitespaceTokenizer
my_project = Project(id_=TEST_PROJECT_ID)
category = my_project.categories[0]
tokenizer = WhitespaceTokenizer()
label = my_project.get_label_by_name('Austellungsdatum')
spans_not_found = label.spans_not_found_by_tokenizer(tokenizer, categories=[category])
for span in spans_not_found:
print(f"{span}: {span.offset_string}")
Span (66, 78): "328927/10103": 328927/10103
Conclusion¶
In this tutorial, we have walked through the essentials of tokenization. We have shown how the Konfuzio SDK can be configured to use different strategies to chunk your input text into tokens, before it is further processed to extract data from it.
We have seen the WhitespaceTokenizer, splitting text into chunks delimeted by white spaces. We have seen the more complex RogexTokenizer, which can be configured to use regular expressions to define delimiters matching any arbitrary regular expression. Furthermore, we have shown how regular expressions can be automatically found to be then used by the RegexTokenizer. We have also seen the Paragraph- and SentenceTokenizer, delimiting text according paragraphs and sentences respectively, and their different modes of use: line_distance for simpler Documents, and detectron for Documents with a more complex structure.